Persistence Store Service
persistence
This is a framework proposal to implement application persistence logic for query-able and non-modeled data (aka, object store), which is needed for many SDN applications like the AAA, AADS and TSDR projects. This framework unifies the common tasks of persisting data so that applications can follow a systematic method to implement their persistence logic with well-defined abstractions and separation of concerns between business and persistence logic. Regardless of the type of underlying database (e.g. relational vs. non-relational) or in-memory implementation (e.g. hash-table) from the business logic’s perspective there should not be a difference in the use of the persistence service. Consumers of a persistence layer need to persist and query data by applying certain filtering and optional sorting criteria. This is especially true for Big Data applications where partial data is commonly retrieved. The API should therefore be simple, extensible, and general enough to allow implementations for different database vendors or in-memory stores.
Everything in the field is well-known, however it has been abstracted in a way a systematic type-safe method is followed.
Modeling data for persistence could be radically different for different data stores (or databases), however interacting with persistence layers is actually very similar. Regardless of the type of database:
The main objective is to follow a common API that clearly separate concerns.
Provide the generic functionality to implement persistence logic that can be selectively changed by additional user-written code to provide application-specific functionality.
Provide an extensible and reusable software platform that includes:
SDN Applications will be able to interact with persisted data in the ways listed below. This functionality is normally assisted by a database management system, but it is also applicable other persistence methods.
NOTE: In the following sections JPA and Cassandra implementations will be included for illustration purposes; to illustrate different type of data stores could be plugged in regardless of the way they model persistent data. That does not necessarily include them as part of the project's scope.
Figure 1 illustrates how the proposed persistence service integrates with the overall Open Daylight architecture. Note that RDBMS and NoSQL databases are shown only to emphasize the fact different types (SQL vs. NoSQL) and multiple instances of databases will be able to run simultaneously with this framework on the controller.
Figure 1 - Persistence Service & ODL Architecture
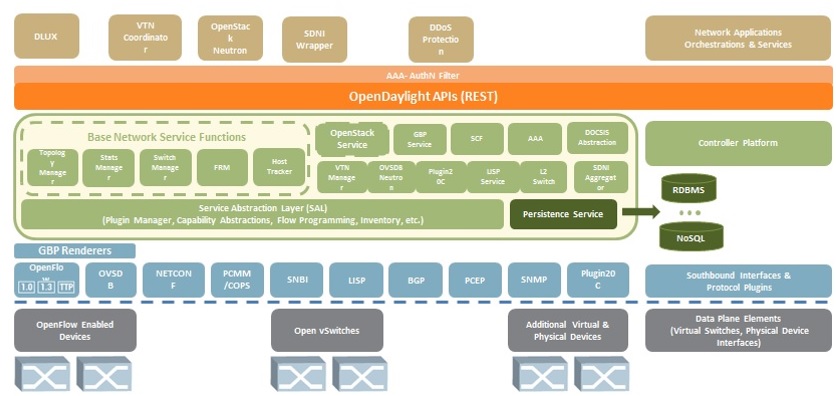
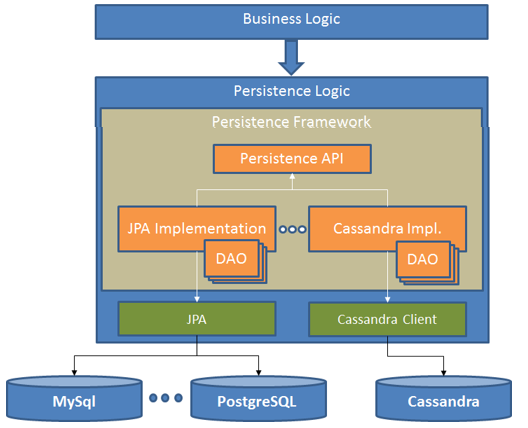
Figure 2 depicts the software architecture:
Figure 2 - Software Architecture
This section introduces a summary of the API. It is not the intent to show the complete API, but just enough detail to see the advantages and design principles followed by the proposal.
The Data Store Service is the public API that is exposed and consumed by the upper layers. Figure 3 shows the static structure of the Data Store Service.
Figure 3 - Data Store Service API
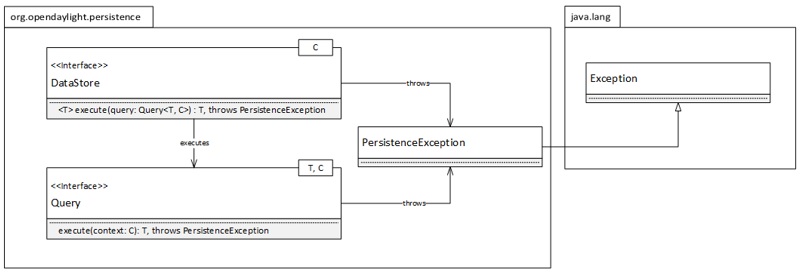
Figure 4 shows the sequence diagram of a high level execution of a Query using a DataStore. Figure 5 illustrates an example using a JPA-based implementation..
Figure 4 - Query Execution Sequence Diagram
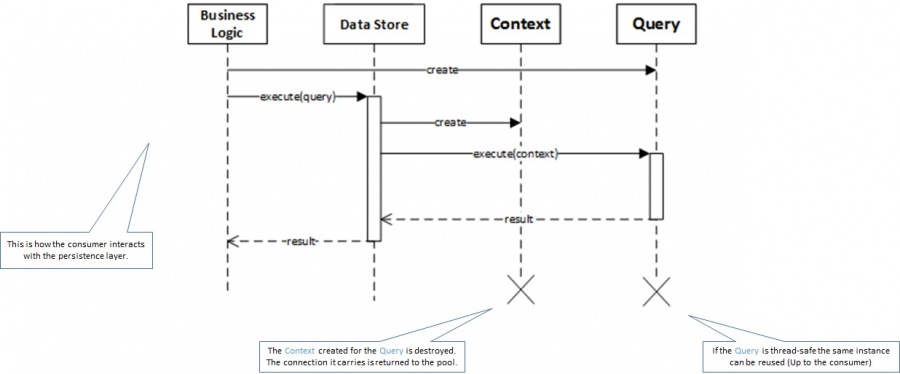
Figure 5 - Query Execution Sequence Diagram
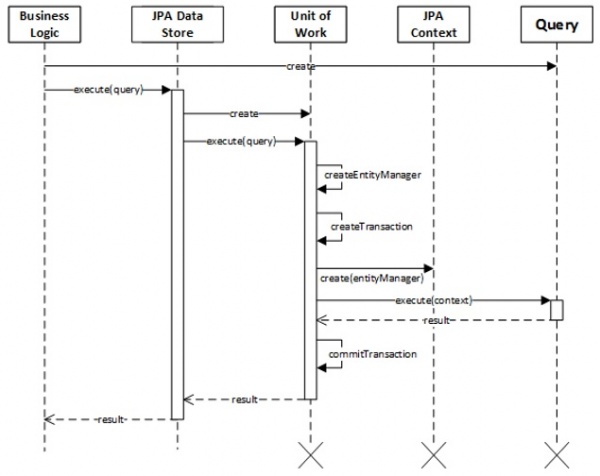
The consumer just needs to create the right query to execute. As part of the persistence logic’s API provided to the consumer, a Query Factory, or set of factories, could be provided to hide queries' implementation details. The DataStore Service API allows consumers to interact with databases in the same way, however replacing the DataStore implementation would affect the business logic since a different set of queries would have to be executed (They needs different contexts). In order to overcome this and allow replacing the database without affecting the consumer code, a Façade interface along with an abstract implementation could be introduced to execute queries using a particular implementation of the DataStore.
A DataStore and queries is everything needed to write persistence logic, however a unified Data Access Object (DAO) API allows creating abstractions and partial implementations for different types of databases, so applications only implement the specifics.
The Data Access Object layer is a restricted API meant to be used just by the persistence logic, more precisely by queries. Figure 6 illustrates the same sequence diagram from Figure 4 extended to show the DAO layer’s role.
Figure 6 - DAO Role during Query Execution Sequence Diagram
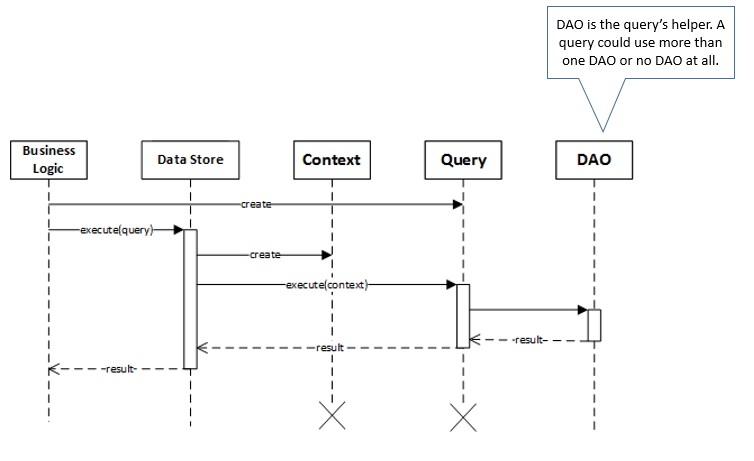
A DAO provides an abstract interface for commonly used CRUD operations without exposing details of the database. The DAO API follows an object mapping approach: Objects are stored in the database and data is retrieved as objects as well.
Figure 7 - Data Access Object (DAO) API
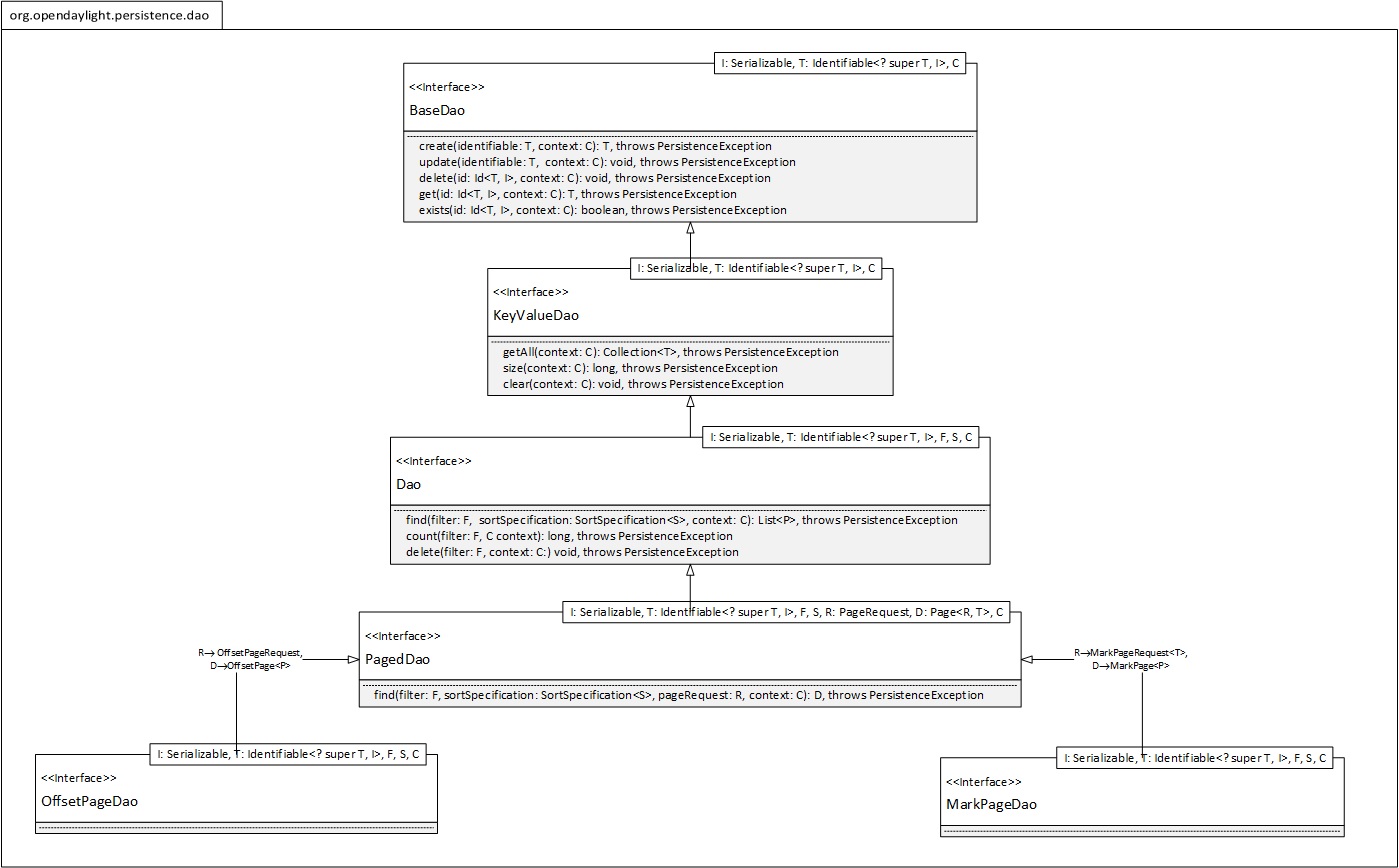
The generic types in the DAO API from Figure 7 include:
Conceptually, for each object to store a DAO in charge of doing so is defined. This DAO takes care of the specifics of the object:
However, It is up to the implementations to define their own abstractions. If the specifics can be defined in a systematic way, then a single DAO could take care of all objects to store. For example, assume the objects are serialized and no filtering or sorting is needed. Another example could be the case of JPA; if no filtering and sorting are needed the specifics are defined by annotating the object.
The DAO API does not cover all the functionality a Data Base Management System usually provides – grouping data for example. And it is not the intent to pollute the API with all possible functionality provided by all types of DBMSs. The purpose of the DAO API (which is extensible in case a particular feature is required to be reusable for an application) is to define functionality that is commonly used by Information Systems.
For special cases where it is desired to take advantage of a particular functionality provided by the underlying database technology, a Query may be implemented where the query’s Context is used directly to get exposure to the database’s native functionality. By using the Context directly a Query gets access to native functionality, which obviously makes porting the code to a different database more difficult. Thus, it is critically important to isolate these parts properly, which is already achieved by encapsulating such code in a Query.
As it is illustrated in the DAO API the type of the associated filter is a generic type and it is responsibility of the DAO to translate such filter to any mechanism understood by the underlying database technology. Thus, the filter could be anything defined by the application, however it will be used across layers (a POJO is a good candidate). The business logic for example would create a filter to retrieve objects from the database. So, filters are also part of the public API exposed to the business logic.
Even though a filter could be anything needed by an application, at the end they represent a set of conditions combined using logical operators.
The persistence framework will provide infrastructure classes to assist on the definition of a filter as illustrated in the example of Figure 8.
Figure 8 - Filter Example

As it is illustrated in the DAO API the type of the associated sort key is a generic type and it is responsibility of the DAO to translate such key to any mechanism understood by the underlying database technology. Thus, the sort key could be anything defined by the application, however it will be used across layers (an enumeration is a good candidate).
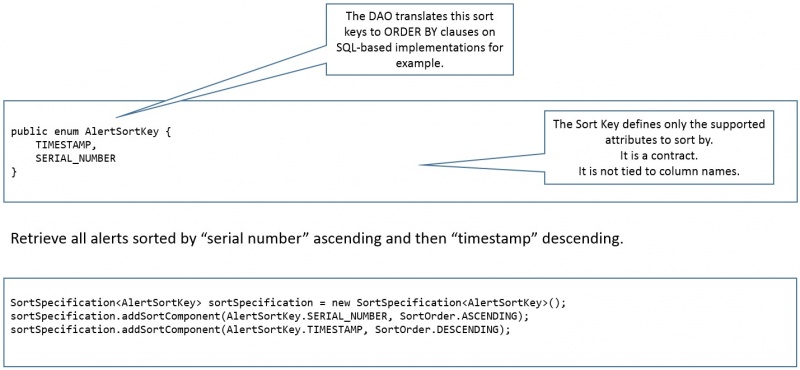
The persistence framework will provide infrastructure classes to assist on the definition of sort specifications as illustrated in the example of Figure 9.
Figure 9 - Sorting Example
The common API allows creating abstract implementations for integration test that are independent of the data store implementation.
Integration testing is a fundamental part of a persistence layer to validate:
Figure 10 depicts the modules that conform the persistence framework. Colors in the diagram represent groups of related modules.
Figure 10 - Module Dependency Diagram
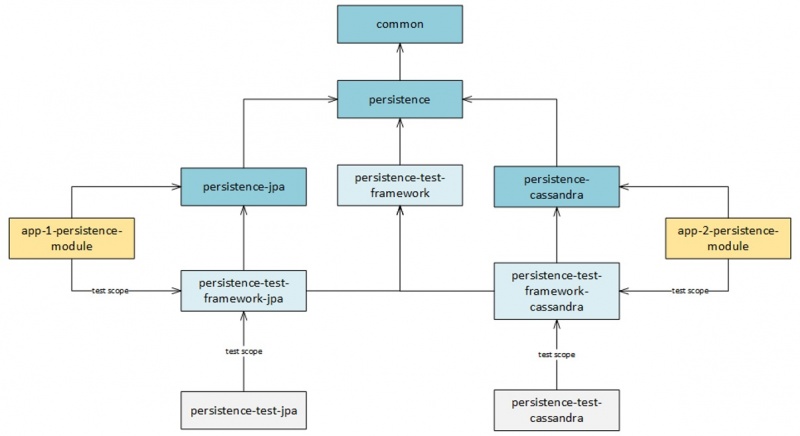
This group of modules are used by applications to implement their persistence logic. This group includes:
This group represent the test tools available to applications to write integration tests. This group includes:
This group is internal to the framework and it includes integration test of the framework itself. This group includes:
This group was added for illustration purposes since these modules are not actually part of the framework. It shows the modules an application would depend on. This group includes:
Applications consuming the JPA implementation of the persistence framework API would depend on the following modules: common, persistence, persistence-jpa, persistence-test-framework, and persistence-test-framework-jpa. Applications consuming the Cassandra implementation of the persistence framework API would depend on the following modules: common, persistence, persistence-cassandra, persistence-test-framework, and persistence-test-framework-cassandra.
This section describes various arguments in favor of and against the persistence framework described in this document.
It is important for an API to be easy to use, but it is even more important to be hard to misuse. Misusages of an API should be noticeable as compilation errors otherwise they will be exhibited as runtime errors.
The API is easy to use because it clearly separates concerns between the consumer (which in most cases is the business logic) and the persistence logic implementation. The concepts used are very common in the database field and design patterns. It defines a set of infrastructure classes to be used at the business layer to deal with model objects and criteria to query data.
The API is hard to misuse because it is strongly typed (type-safe). Type errors generate compilation errors which minimizes runtime errors. Changes on an object’s contract should produce compilation errors in all places the change has to be addressed. This forces us to think how the change impacts the related code. No compilation errors produced as the result of changing an object’s contract means errors will exhibit at runtime. Automated test is good, but the compiler is better; try catching errors at compile time.
In database projects it is pretty easy to introduce type vulnerabilities; especially if languages like SQL are used because database operations have to be specified as a String, which makes difficult to detect type and typo errors. Also, lots of Database Management Systems (Like JPA 1.0) brakes encapsulation exposing the internals of an object: To write a query the name of the column or in the JPA world the name of a private field must be known. This makes the internals of an object public which is a design issue. After releasing, it might never be possible to change the internals of an object if they were exposed because of queries.
Runtime errors are expensive. In order to catch them in production phase proper automated test that exercise the part of code where errors were introduced must be written. It cannot be always guaranteed 100% test coverage. If no automated test is available the application must be manually run using the feature that generates the error. Parts of the application where errors were introduced might never be run in production phase until the costumer finds it. Even if the problem is log, the application has to be run, the feature that generates the error used and then the log files reviewed to detect the error (Too expensive).
The persistence API defines common behavior needed by Information Systems. It defines the behavior in a high abstraction level regardless of any feature or especial considerations imposed by any type of database provider. As a result, the API consolidates persistence behaviors that can be provided by any type of database, even when data modeling is too different as in the case of Relational and Non-relational. It can be seen in Listing 1 how similar for the consumer is to deal with different typed of databases.
Writing persistence logic for different types of databases with radical differences (Like SQL or Relational vs. NoSQL or non-relational) is still different. For example, a JPA-based DAO is completely different than a Cassandra-based DAO. This framework does not unify implementations but APIs, so particularities of the database are not exposed to the consumer allowing database backends to be replaced without affecting the way the consumer interacts with the new database or data store.
The persistence API does not cover all the functionality a Data Base Management System (DBMS) usually provides. And it is not the intent to pollute the API with all possible functionality provided by all types of DBMSs. However, the API is extensible in case a particular feature is required for an application. For special cases where it is desired to take advantage of a particular functionality provided by the underlying database technology, either the DAO API may be extended to force all DAO implementations to provide such feature, or a Query may be implemented where the query’s Context is used directly to get exposure to the database’s native functionality. By using the Context directly a Query gets access to native functionality, which obviously makes porting the code to a different database more difficult - however these especial cases are properly isolated by encapsulating such code in a Query.
The persistence API favors loosely coupling designs by separating concerns between business logic and persistence logic. Internals of the persistence logic are not exposed to the consumer. Additionally, by defining a vocabulary of objects along with a well-defined role, the API favors high cohesion since it would be very difficult to add non-related functionality to an object with a single purpose.
The persistence API was defined without taking into consideration any database provider. Thus, specific implementations do not affect the API definition nor its usage. Impact in the consumer is minimum if the database is replaced by a different provider.
The framework provides infrastructure classes to write integration test.
The persistence process involves creating several objects: The object to store (Identifiable), Storable (If the data transfer patter is used, which is recommended), Filter, Sort Specification, DAO and the Query. And regular conversions between Transportable-Storable are performed. This may represent an overhead from the performance point of view.
Note that creating more objects not necessarily means harder to maintain. For the maintainability point of view it is actually better to have more objects where each object has a single well-defined purpose, which is the paradigm followed by this persistence API.
A simplistic persistence layer would just need a connection to the database and the data to persist, which seems to be easy to use but it is actually hard to maintain at the end – at the end a bunch of string-based queries are generated which are hard to keep track of. By creating those objects this persistence API defines a systematic way of writing persistence logic. It is more work up front, but as the systems grows it remains easy to maintain.
Most queries in Information Systems don’t actually need to exhibit high performance behavior. A real time application or a latency sensitive application wouldn’t put the database in the critical path. Big-data systems or extremely queried systems usually scale out by adding more nodes to distribute the load. Thus, it is more important to create maintainable systems. Do not optimize early; optimize code when an issue has been detected by using a profiler. Highly optimized code is normally hard to read and by definition hard to maintain (because introduced changes may defeat the optimization). However, if an application needs a high performance query, a custom Query could be created that makes no usage of any additional object: It would receive raw data as parameters and it would use the Context directly to get exposure to the database native functionality, skipping the DAO implementation and the conversions between Identifiable-Storable if the data transfer pattern is used.
The persistence API is easy to use for the consumer (Business logic), and it defines a systematic way to implement persistence logic. However, when it comes to implement the DAOs, the complexity depend on the abstractions provided by the implementation (Abstract implementations are not unified, which is normal and expected). For example, JPA based DAOs are easier to implement than Cassandra DAOs. JPA abstract DAOs already implement 80% of the work, the other 20% (which addresses only the specifics) is implemented by the concrete classes. In the other hand, Cassandra abstract DAOs implements only the 20% and concrete implementations have to implement the rest. The Cassandra implementation offers tools like Custom Secondary Indexes to assist the creation of DAOs, but still they are way more complex than their JPA counterparts.
Different databases deal differently with schemas. That is why it is very hard to include schema definition as part of the persistence API. Cassandra for example offers a way to create tables programmatically, while JPA can create and deploy the schema automatically by introspecting the entities. This persistence framework doesn’t directly address schema generation; the way applications deal with the schema depends on the implementation.
Who is, or will be working on this effort?
Fabiel Zuniga – fabiel.zuniga@hp.com ODL: fabiel.zuninga
Nachiket Abhyankar - nabhyank@hp.com ODL: nachiket331
Mark Mozolewski - mark.mozolewski@hp.com ODL: mark.mozolewski
Liem Manh Nguyen - liem_m_nguyen@hp.com ODL:liemmn
TBD - Looking for other committers
This project will consist of contributing some existing code as well as developing new code. Code will be made available for review by ODP and Linux Foundation after it has been approved by contributing organizations
The Persistence Store Service project formally joins the OpenDaylight Lithium Simultaneous Release and agrees to the activities and timeline documented on the Lithium Release Plan Page